2018-04-22 13:55:00



来源:电子发烧友网
1952年,贝尔实验室(Bell Labs)制造一台6英尺高自动数字识别机“Audrey”,它可以识别数字0~9的发音,且准确度高达90%以上。并且它对熟人的精准度高,而对陌生人则偏低。
1956年,普林斯顿大学RCA实验室开发了单音节词识别系统,能够识别特定人的十个单音节词中所包含的不同音节。
1959年,MIT的林肯实验室开发了针对十个元音的非特定人语音识别系统。

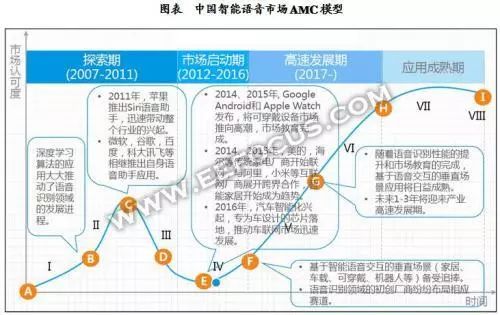
智能语音的发展过程历史详细概述
二十世纪六十年代初,东京无线电实验室、京都大学和NEC实验室在语音识别领域取得了开拓性的进展,各自先后制作了能够进行语音识别的专用硬件。
1964年的世界博览会上,IBM向世人展示了数字语音识别的“shoe box recognizer”。
二十世纪七十年代,语音识别的研究取得了突破性的进展,研究重心仍然是孤立词语语音识别。
1971年,美国国防部研究所(Darpa)赞助了五年期限的语音理解研究项目,希望将识别的单词量提升到1000以上。参与该项目的公司和学术机构包括IBM、卡内基梅隆大学(CMU)、斯坦福研究院。就这样,Harpy在CMU诞生了。不像之前的识别器,Harpy可以识别整句话。
二十世纪八十年代,NEC提出了二阶动态规划算法,Bell实验室提出了分层构造算法,以及帧同步分层构造算法等。同时,连接词和大词汇量连续语音的识别得到了较大发展,统计模型逐步取代模板匹配的方法,隐马尔科夫模型(HMM)成为语音识别系统的基础模型。
八十年代中期,IBM创造了一个语音控制的打字机—Tangora,能够处理大约20000单词。IBM的研究就是基于隐形马尔科夫链模型(hidden Markov model),在信号处理技术中加入统计信息。这种方法使得在给定音素情况下,很有可能预测下一个因素。
1984年,IBM发布的语音识别系统在5000个词汇量级上达到了95%的识别率。
1985年AT&T贝尔实验室建造了第一个智能麦克风系统,用来研究大室内空间的声源位置追踪问题。
1987年开始,国家开始执行963计划后,国家863智能计算机主题专家组为语音识别研究立项,每两年一次。
1987年12月,李开复开发出世界上第一个“非特定人连续语音识别系统”。
1988年,卡耐基梅隆大学结合矢量量化技术(VQ),用VQ/HMM方法开发了世界上第一个非特定人大词汇量连续语音识别系统SPHINX,能够识别包括997个词汇的4200个连续语句。
同年,清华大学和中科院声学所在大词库汉语听写机的研制上取得了突破性进展。
1990年,声龙发布了第一款消费级语音识别产品Dragon Dictate,价格高达9000美元。
1992年,IBM引入了它的第一个听写系统,称为“IBM Speech Server Series (ISSS)”。
1992年研发的Sphinx-II在同年美国国防部先进技术研究计划署(DARPA)资助的语音基准评测中获得了最高的识别准确度,这主要得益于其在高斯混合和马尔可夫状态层次上用栓连参数平衡了可训练性和高效性。
1995年,Windows 95上首次搭载微软SAPI,它使应用程序开发者能够在Windows上创建语音程序。
1995年,AT&T研究院的 Dave Ladd, Chris Ramming, Ken Rehor 以及 Curt Tuckey 在头脑风暴关于互联网会如何改变电话应用的时候,产生了一些新的想法:为什么不设计这样一个系统来运行一种可以解析某种语音标记语言的语音浏览器,用来把互联网的内容和服务提供到千家万户的电话上。于是,AT&T就开始“电话网络项目”(Phone Web Project)。之后,Chris继续留在AT&T,Ken去了朗讯,Dave和Curt去了摩托罗拉。(1999年初的时候,他们分别在各自的公司迈出了语音标记语言规范实质性的第一步。因为他们的密友关系,这几家公司合作成立了一个VoiceXML论坛组织,IBM也作为一个创始公司加入了进来。)
1997年IBM ViaVoice首个语音听写产品问世,你只要对着话筒喊出要输入的字符,它就会自动判断并且帮你输入文字。次年又开发出可以识别上海话、广东话和四川话等地方口音的语音识别系统ViaVoice’ 98。
1998年,微软在北京成立亚洲研究院,将汉语语音识别纳入重点研究方向之一。
2001年,比尔盖茨在美国消费电子展上展示了一台代号为MiPad的原型机。Mipad展现了语音多模态移动设备的愿景。
2002年,中科院自动化所及其所属模式科技公司推出了“天语”中文语音系列产品——Pattek ASR,结束了该领域一直被国外公司垄断的局面。
2002年,美国国防部先进技术研究计划署(DARPA)首先启动了EARS项目和TIDES 项目; 由于EARS项目过于敏感,EARS和TIDES两个项目合并为“全球自主语言开发”(Global Autonomous Language Exploitation,GALE)。GALE目标是应用计算机软件技术对海量规模的多语言语音和文本进行获取、转化、分析和翻译。
2006年,辛顿(Hinton)提出深度置信网络(DBN),促使了深度神经网络(Deep Neural Network,DNN)研究的复苏,掀起了深度学习的热潮。
2009年,辛顿以及他的学生默罕默德(D. Mohamed)将深度神经网络应用于语音的声学建模,在小词汇量连续语音识别数据库TIMIT上获得成功。
2009年微软Win7集成语音功能。
2010年Google Vioce Action支持语音操作与搜索。
2011年初,微软的DNN模型在语音搜索任务上获得成功。
同年科大讯飞将DNN 首次成功应用到中文语音识别领域,并通过语音云平台提供给广大开发者使用。
2011年10月,苹果iPhone 4S发布,个人手机助理Siri诞生,人机交互翻开新篇章。
2012年,科大讯飞在语音合成领域首创RBM技术。
2012年,谷歌的智能语音助手Google Now 的形式出现在众人面前,用在安卓 4.1 和 Nexus 手机上。
2013年,Google发布Google Glass,苹果也加大了对iWatch的研发投入,穿戴式语音交互设备成为新热点。
同年,科大讯飞在语种识别领域首创BN-ivec技术。
2014 年,思必驰推出首个可实时转录的语音输入板。
2014年11月,亚马逊智能音箱Echo发布。
2015 年,思必驰推出首个可智能打断纠正的语音技术。
2016年,Google Assistant伴随Google Home 正式亮相,抢夺亚马逊智能音箱市场。(亚马逊Echo在2016年的智能音箱市场占有率达到了巅峰的88%)
同年,科大讯飞上线DFCNN(深度全序列卷积神经网络,Deep Fully Convolutional Neural Network)语音识别系统。
同年11月,科大讯飞、搜狗、百度先后召开发布会,对外公布语音识别准确率均达到“97%”。
2017年3月,IBM结合了 LSTM 模型和带有 3 个强声学模型的 WaveNet 语言模型。“集中扩展深度学习应用技术终于取得了 5.5% 词错率的突破”。相对应的是去年5月的6.9%。
2017年8月,微软发布新的里程碑,通过改进微软语音识别系统中基于神经网络的听觉和语言模型,在去年基础上降低了大约12%的出错率,词错率为5.1%,声称超过专业速记员。相对应的是去年10月的5.9%,声称超过人类。
2017年12月,谷歌发布全新端到端语音识别系统(State-of-the-art Speech Recognition With Sequence-to-Sequence Models),词错率降低至5.6%。相对于强大的传统系统有 16% 的性能提升。
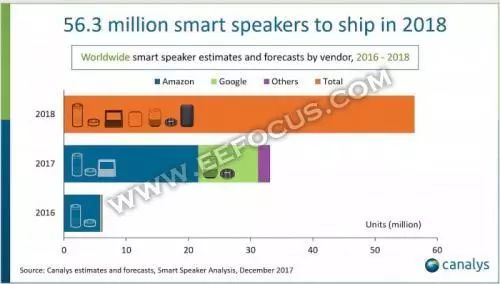
市场分析公司Canalys在2018年1月分布一份报告,其预测2018年将是普及智能音箱的“决定性一年”,相比全年出货量刚过3000万台的2017年,2018年智能音箱全球出货量预计将达到5630万台。
智能语音的发展过程历史详细概述
中投顾问发布的《2018-2022年中国智能语音行业深度调研及投资前景预测报告》显示我国智能语音市场整体处于启动期,智能车载,智能家居,智能可穿戴等垂直领域处于爆发前夜。